
I just shipped version 4.1 of MikroORM, the TypeScript ORM for Node.js, and I feel like this particular release deserves a bit more attention than a regular feature release.

So what changed?
This release had only one clear goal in mind — the performance. It all started with an issue pointing out that flushing 10k entities in a single unit of work is very slow. While this kind of use case was never a target for me, I started to see all the possibilities the Unit of Work pattern offers.
Batch inserts, updates and deletes
The biggest performance killer was the amount of queries — even if the query is as simple and optimised as possible, firing 10k of those will be always quite slow. For inserts and deletes, it was quite trivial to group all the queries. A bit more challenging were the updates — to batch those, MikroORM now uses case statements.
As a result, when you now flush changes made to one entity type, only one query per given operation (create/update/delete) will be executed. This brings significant difference, as we are now executing fixed number of queries (in fact the changes are batched in chunks of 300 items).
for (let i = 1; i <= 5; i++) {
const u = new User(`Peter ${i}`, `peter+${i}@foo.bar`);
em.persist(u);
}
await em.flush();
// insert into `user` (`name`, `email`) values
// ('Peter 1', 'peter+1@foo.bar'),
// ('Peter 2', 'peter+2@foo.bar'),
// ('Peter 3', 'peter+3@foo.bar'),
// ('Peter 4', 'peter+4@foo.bar'),
// ('Peter 5', 'peter+5@foo.bar');
for (const user of users) {
user.name += ' changed!';
}
await em.flush();
// update `user` set
// `name` = case
// when (`id` = 1) then 'Peter 1 changed!'
// when (`id` = 2) then 'Peter 2 changed!'
// when (`id` = 3) then 'Peter 3 changed!'
// when (`id` = 4) then 'Peter 4 changed!'
// when (`id` = 5) then 'Peter 5 changed!'
// else `priority` end
// where `id` in (1, 2, 3, 4, 5)
em.remove(users);
await em.flush();
// delete from `user` where `id` in (1, 2, 3, 4, 5)
JIT compilation
Second important change in 4.1 is JIT compilation. Under the hood, MikroORM now first generates simple functions for comparing and hydrating entities, that are tailored to their metadata definition. The main difference is that those generated functions are accessing the object properties directly (e.g. o.name), instead of dynamically (e.g. o[prop.name]), as all the information from metadata are inlined there. This allows V8 to better understand the code so it is able to run it faster.
Results
Here are the results for a simple 10k entities benchmark:
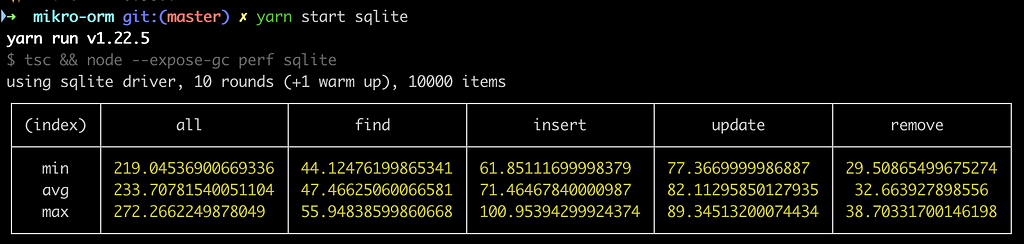
In average, inserting 10k entities takes around 70ms with sqlite, updates are a tiny bit slower. You can see results for other drivers here: https://github.com/mikro-orm/benchmark.

Acknowledgement
Kudos to Marc J. Schmidt, the author of the initial issue, as without his help this would probably never happen, or at least not in near future. Thanks a lot!
Like MikroORM? ⭐️ Star it on GitHub and share this article with your friends. If you want to support the project financially, you can do so via GitHub Sponsors.